
Der ARC-Preis ist ein mit über 1.000.000 Dollar dotierter öffentlicher Wettbewerb, der darauf abzielt, (Open-Source) Fortschritte im Bereich der Künstlichen Allgemeinen Intelligenz voranzutreiben. Er soll neue Ideen inspirieren und den Fortschritt auf dem Gebiet der Künstlichen Allgemeinen Intelligenz (KI). Mit dem ARC-AGI-Benchmark (Abstraction and Reasoning Corpus for Artificial General Intelligence) soll gemessen werden, wie gut ein KI-System neue Aufgaben verallgemeinern kann, was als ein Schlüsselaspekt von Intelligenz gilt.
Details zum ARC-Preis:
- Ziel des ARC-Preises 2024 war es, eine Punktzahl von 85 % auf dem ARC-AGI Private Evaluation Set zu erreichen. Der Wettbewerb lief von Juni bis November 2024. Zu den Preisen gehörten ein Hauptpreis in Höhe von 600.000 USD für das erste Team, das das 85%-Ziel erreicht, sowie weitere Preise für Fortschritte und eingereichte Arbeiten.
- Der Wettbewerb wurde auf Kaggle ausgetragen, wo die Teilnehmer versuchten, 100 Aufgaben aus dem ARC-AGI Private Evaluation Set auf einer virtuellen Maschine mit begrenzten Ressourcen zu lösen. Die Teilnehmer mussten ihre Lösungen als Open Source zur Verfügung stellen, um für Preise in Frage zu kommen.
- Die höchste Punktzahl, die während des Wettbewerbs 2024 erreicht wurde, war 55,5 % von MindsAI, obwohl sie nicht für einen Preis in Frage kamen, da sie ihre Lösung nicht offengelegt hatten. Diese Punktzahl wurde von o3 von OpenAI übertroffen, das Ende 2024 75,7 % erreichte, was darauf hindeutet, dass der Benchmark selbst in naher Zukunft gesättigt sein könnte.
- Der Wettbewerb umfasste auch ein zweites öffentliches Leaderboard mit lockeren Rechenbeschränkungen und Internetzugang. Diese Rangliste diente zur Bewertung der Leistung unter Verwendung kommerziell verfügbarer APIs.
- Im Rahmen des ARC-Preises wurden auch „Paper Awards“ vergeben, um neuartige Konzepte unabhängig von der erreichten Punktzahl zu würdigen, wobei mehrere Arbeiten, die neue Techniken beschreiben, ausgezeichnet wurden.
- Der ARC-Preis soll ein jährlicher Wettbewerb sein, bis der ARC-AGI-Benchmark besiegt und eine öffentliche Referenzlösung vorgestellt wird. Die Organisatoren planen, den Wettbewerb 2025 auf der Grundlage der Erfahrungen aus der Veranstaltung 2024 neu zu gestalten.
- Der ARC-Preis hat die Entwicklung verschiedener Tools, Datensätze und Repositories angeregt, um die Forschung und Entwicklung im Zusammenhang mit ARC-AGI zu unterstützen, darunter domänenspezifische Sprachen, Rahmenwerke für die Datengenerierung und interaktive Web-Tools.
Mit dem ARC-Preis soll die offene Forschung im Bereich der Künstlichen Intelligenz gefördert werden, da ein Großteil der Pionierforschung im Bereich der Künstlichen Intelligenz nicht mehr von Industrielabors veröffentlicht wird. Ziel ist es, Forscher zu ermutigen, neue Techniken zu entwickeln und sie offen mit der Gemeinschaft zu teilen. Der Wettbewerb soll auch dazu beitragen, den ARC-AGI-Benchmark selbst zu verbessern.
Wie funktioniert der ARC-Preis?
Der ARC-AGI Benchmark wurde entwickelt, um die allgemeine Intelligenz und die Effizienz des Kompetenzerwerbs in KI-Systemen zu messen. Und so funktioniert es:
Aufgabenstruktur
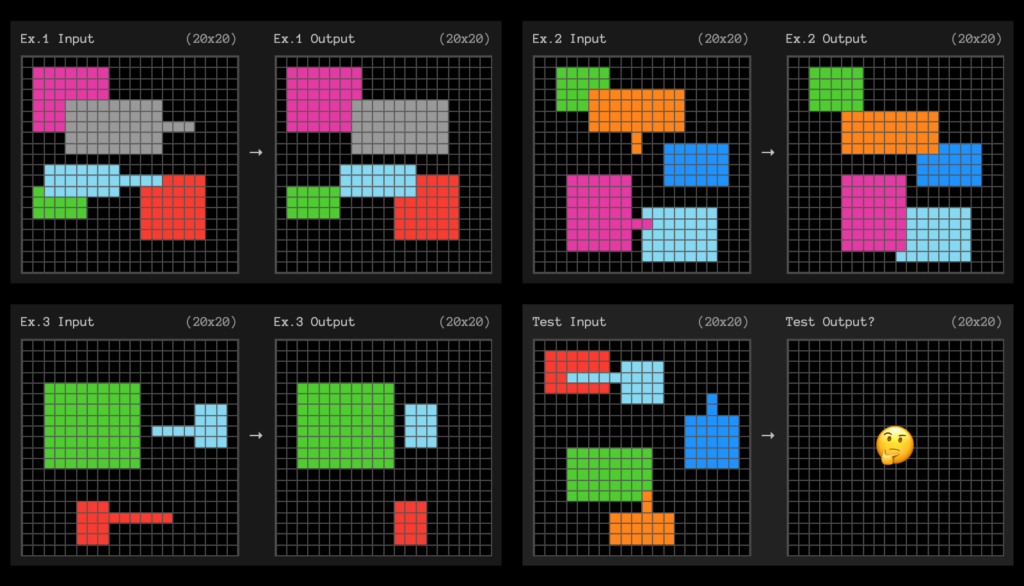
- Jede Aufgabe in ARC-AGI besteht aus Input-Output-Beispielen, die als Raster dargestellt werden.
- Die Raster können jede Größe von 1x1 bis 30x30 haben.
- Jedes Quadrat im Raster kann eine von zehn Farben haben.
Bewertungsverfahren
- Um eine Aufgabe zu lösen, muss das KI-System ein pixelgenaues, korrektes Ausgaberaster für die Bewertungseingabe erzeugen, einschließlich der Bestimmung der korrekten Abmessungen des Ausgaberasters.
- Der Benchmark umfasst öffentliche Trainings- und Bewertungssätze sowie einen privaten Bewertungssatz.
- Der öffentliche Trainingssatz enthält 400 Aufgabendateien für das Algorithmustraining.
- Der öffentliche Evaluierungssatz enthält außerdem 400 Aufgabendateien zur Prüfung der Algorithmusleistung.
- Der private Bewertungssatz, der für die offizielle Rangliste verwendet wird, enthält 100 Aufgabendateien.
Punktevergabe
- Die Leistung wird anhand des Prozentsatzes der korrekten Vorhersagen in der privaten Bewertungsgruppe (100 Aufgaben) gemessen.
- Für jede Aufgabe muss das System für jedes Testeingabegitter genau 2 Ausgaben vorhersagen.
- Eine Aufgabe gilt nur dann als gelöst, wenn die vorhergesagte Ausgabe genau mit der Grundwahrheit übereinstimmt.
Hauptmerkmale
- Neuartige Aufgaben: Jede Aufgabe im Datensatz folgt einer anderen Logik, so dass die Systeme nicht im Voraus auf bestimmte Aufgaben vorbereitet werden können.
- Grundwissen Prioritäten: Der Benchmark geht nur von grundlegendem Vorwissen aus, das Menschen typischerweise vor dem vierten Lebensjahr erwerben, z. B. Objektivität, grundlegende Topologie und elementare Ganzzahlarithmetik.
- Kein Spezialwissen: Zur Lösung der Aufgaben sind keine speziellen Kenntnisse der Welt oder Sprachkenntnisse erforderlich.
- Menschliche Verifizierung: Alle Aufgaben wurden von mindestens zwei MINT-Fachleuten überprüft, um sicherzustellen, dass sie von Menschen gelöst werden können.
Schwierigkeitsgrad
- Im Jahr 2024 liegt die KI-Leistung von ARC-AGI auf dem neuesten Stand der Technik bei 55,5 % der privaten Auswertungsmenge.
- Die menschliche Leistung liegt im Durchschnitt zwischen 73,3 % und 77,2 % bei den öffentlichen Sätzen.
Durch die Konzentration auf die Effizienz des Kompetenzerwerbs und nicht auf die aufgabenspezifische Leistung soll ARC-AGI ein genaueres Maß für die allgemeine Intelligenz von KI-Systemen liefern.
Warum ist das Lösen von ARC-Aufgaben für KIs schwierig?
Das Lösen von ARC-Rätseln ist für KI-Systeme aufgrund mehrerer Schlüsselfaktoren eine besondere Herausforderung:
Komplexität des Problemlösungsprozesses
- Anforderung an das Lernen anhand von wenigen Beispielen: ARC-Rätsel sind so konzipiert, dass sie die Fähigkeit einer KI zur Verallgemeinerung aus einer begrenzten Anzahl von Beispielen (3-5) bewerten. Diese Anforderung des „few-shot learning“ bedeutet, dass sich KI-Modelle nicht auf umfangreiche Trainingsdaten oder das Auswendiglernen von Daten verlassen können, wie es beim traditionellen maschinellen Lernen üblich ist. Stattdessen müssen sie zugrundeliegende Prinzipien extrahieren und auf neue Situationen anwenden, ähnlich wie Menschen lernen.
- Widerstandsfähigkeit gegen Auswendiglernen: Die Aufgaben sind speziell so konzipiert, dass sie sich einfachen Auswendiglernstrategien widersetzen. Sie erfordern oft das Verständnis abstrakter Konzepte und Beziehungen und nicht nur das Erkennen von Mustern aus früheren Beispielen. Wie François Chollet, der Schöpfer des ARC-Benchmarks, feststellte, sind diese Aufgaben für Menschen einfach, aber für aktuelle KI-Systeme schwierig, da sie kein komplexes Wissen erfordern, sondern eher die Fähigkeit zu denken und sich anzupassen.
Art der Rätsel
- Abstraktes Denken: Die Rätsel erfordern ein tiefes Verständnis für abstraktes Denken, Logik und manchmal sogar Physik. Die KI muss Muster erkennen und logische Schlussfolgerungen aus vorgegebenen Beispielen ziehen, was wesentlich komplexer sein kann, als es auf den ersten Blick scheint.
- Vielfältige Aufgaben: Jedes Rätsel stellt ein eigenes Lernproblem dar, so dass es für KI schwierig ist, eine einzige Strategie für verschiedene Aufgaben anzuwenden. Diese Vielfalt an Problemtypen zwingt KI-Systeme dazu, flexible Argumentationsfähigkeiten zu entwickeln, anstatt sich auf feste Algorithmen oder Heuristiken zu verlassen.
Grenzen der aktuellen AI-Modelle
- Mangel an echtem Verständnis: Viele moderne KI-Systeme, einschließlich großer Sprachmodelle (LLMs), arbeiten in erster Linie durch fortgeschrittenes Auswendiglernen und statistische Korrelation und nicht durch echtes Verständnis. Das bedeutet, dass sie zwar bei bestimmten Aufgaben mit großen Datensätzen gute Leistungen erbringen können, sich aber mit dem abstrakten Denken, das für ARC-Puzzles erforderlich ist, schwer tun.
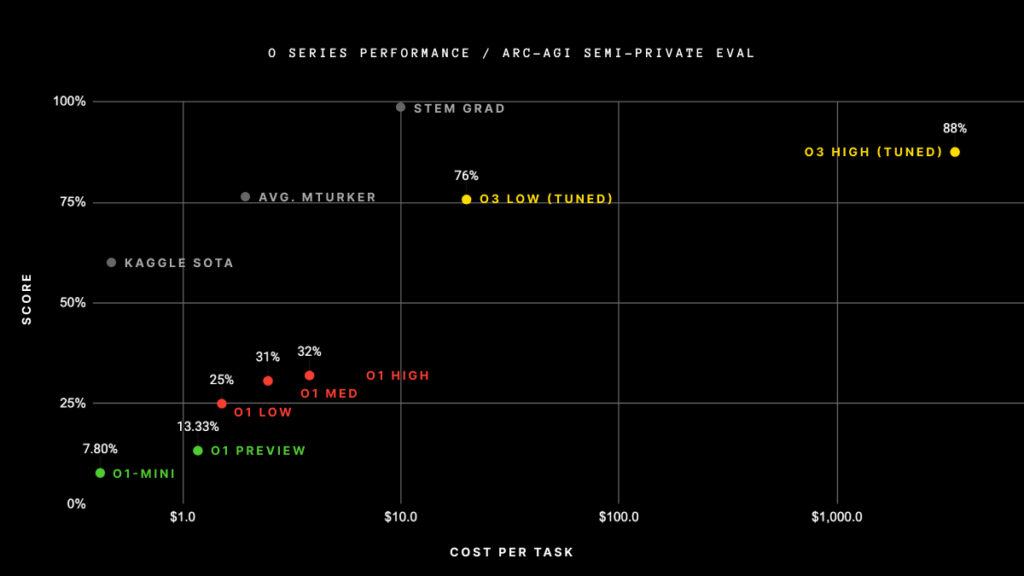
- Hohe Fehlerquoten: Selbst mit Brute-Force-Suche oder Strategien zur Minimierung der Beschreibungslänge haben aktuelle KI-Lösungen bei ARC-Aufgaben nur begrenzten Erfolg gezeigt. So haben die leistungsfähigsten Modelle bei diesen Rätseln nur eine Genauigkeit von etwa 34 % erreicht (o3 ist die bemerkenswerte Ausnahme Ende 2024), während die menschliche Leistung im Durchschnitt zwischen 85 % und 100 % liegt.
Zusammenfassend lässt sich sagen, dass die Kombination aus den Anforderungen des Lernens in wenigen Schritten, dem Widerstand gegen das Auswendiglernen, dem Bedarf an abstraktem Denken und den Grenzen der aktuellen KI-Modelle zu den Schwierigkeiten der KI bei der Lösung von ARC-Rätseln beiträgt. Diese Herausforderungen verdeutlichen die Kluft zwischen den kognitiven Fähigkeiten des Menschen und den derzeitigen Möglichkeiten der künstlichen Intelligenz, echte Verallgemeinerungs- und Schlussfolgerungsfähigkeiten zu erreichen.
Diese Lücke verkleinert sich rasch, und 2025 wird eine neue Version des Benchmarks - ARC-AGI-2 - eingeführt. Sie wird seit 2022 entwickelt und soll den Stand der Technik neu definieren. Das Ziel ist es, die AGI-Forschung mit strengen, hochwirksamen Bewertungen voranzutreiben, die die derzeitigen Grenzen von KI-Systemen aufzeigen. Vorläufige Tests von ARC-AGI-2 zeigen, dass es sowohl wertvoll als auch extrem herausfordernd sein wird, selbst für fortgeschrittene Modelle wie o3. Der Start von ARC-AGI-2 in Verbindung mit dem ARC-Preis 2025 ist für das späte erste Quartal geplant.
