
In the world of artificial intelligence (AI), data is the main ingredient. But just like raw ingredients need preparation before they become a delicious meal, data must be transformed into a palatable format for AI systems, particularly large language models (LLMs), to "digest." This is where embeddings enter the kitchen, serving as the secret sauce that makes data delectable for AI consumption.
What Are Embeddings?
Embeddings are like AI's universal translator. They take the messy, diverse world of human language and convert it into a form that computers can understand and work with efficiently. Imagine trying to explain the concept of "hot" to a computer. You could list synonyms, describe temperature, or give examples. Embeddings do something similar, but in a much more sophisticated and numerical way.
Deep Dive: Vector Representation
At their core, embeddings are vector representations of data. A vector is simply a list of numbers. For example, the word "house" might be represented as:
[0.2, -0.5, 0.1, 0.8, -0.3]Each number in this vector corresponds to a dimension in a multi-dimensional space. The values in each dimension capture different aspects of the word's meaning.
The Recipe for Embeddings
- Start with Raw Data: This could be words, sentences, or even entire documents. Example: Let's say we're working with the sentence "The cat sat on the mat."
- Apply Neural Magic: Using clever neural network techniques, we transform each piece of data into a list of numbers (a vector). For instance, a simple Word2Vec model might process our sentence like this:
- "The" → [0.1, -0.2, 0.3, ...]
- "cat" → [0.5, 0.1, -0.3, ...]
- "sat" → [-0.2, 0.4, 0.1, ...] ...and so on.
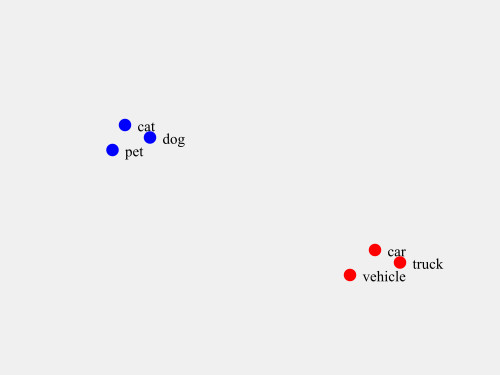
- Season with Meaning: These numbers aren't random. They're carefully crafted to capture the essence and relationships of the original data. In our example, the vector for "cat" might end up closer to vectors for "dog" or "pet" than to "automobile" or "skyscraper".
- Serve in a Multi-Dimensional Space: These number lists (vectors) are placed in a vast multi-dimensional space where similar items cluster together.
Why Embeddings Matter for AI
- Meaning in Numbers: Embeddings allow AI to understand that "dog" is more similar to "puppy" than to "logarithm," all through numerical relationships. Example: In a well-trained embedding space, the cosine similarity between "dog" and "puppy" might be 0.8, while between "dog" and "logarithm" it could be 0.1.
- Efficiency: Instead of dealing with millions of unique words, AI can work with compact number lists, speeding up processing and reducing memory usage. Example: A vocabulary of 100,000 words, each represented by a 300-dimension vector, would only require about 120MB of memory.
- Revealing Hidden Patterns: Embeddings can uncover relationships in data that might not be obvious to human observers. Example: Word embeddings have been used to reveal gender biases in language, like the association of "doctor" with male terms and "nurse" with female terms.
- Bridging Languages: In machine translation, embeddings can help find equivalents across languages by mapping words with similar meanings close to each other in the embedding space. Example: The English word "dog" and the Spanish word "perro" might have similar vector representations in a multilingual embedding space.
Embeddings in Action
Let's look at a few ways embeddings spice up AI applications:
- Recommendation Systems: By embedding user preferences and item characteristics, AI can suggest products or content you're likely to enjoy. Example: Netflix uses embeddings to represent both users and movies. If your viewing history puts you close to sci-fi action movies in the embedding space, you're more likely to get those recommendations.
- Search Engines: Embeddings help search engines understand the intent behind your queries, not just matching keywords. Example: A search for "java" might return results about both coffee and programming, as the embedding for "java" captures both meanings.
- Sentiment Analysis: By capturing the nuanced meanings of words, embeddings enable AI to better understand the emotions expressed in text. Example: The sentence "This movie is sick!" could be correctly identified as positive, as the embedding for "sick" in this context would be closer to positive sentiment words.
- Language Translation: Embeddings form the foundation for modern translation systems, helping to preserve meaning across languages. Example: When translating "I love you" to French, the system might use the embeddings of these words to find the closest equivalent expression "Je t'aime", rather than a word-for-word translation.
The Evolution of Embeddings
Embeddings have come a long way:
- Word2Vec: One of the pioneers, turning words into vectors based on their context. Example: In the sentence "The quick brown fox jumps over the lazy dog", Word2Vec would learn that "fox" and "dog" are somehow related, as they appear in similar contexts.
- GloVe: Improved on Word2Vec by considering global word-word co-occurrence statistics. Example: GloVe might notice that "ice" and "steam" often appear in similar contexts with words like "water", "solid", and "gas", helping it to learn the relationship between these concepts.
- FastText: Extended embeddings to handle subwords, helping with rare words and typos. Example: Even if it hasn't seen the word "unfriendliest", FastText can generate a meaningful embedding for it by combining embeddings of "un-", "friend", "-li-", and "-est".
- Contextual Embeddings: Modern approaches like BERT and GPT generate dynamic embeddings that change based on context, capturing even more nuanced meanings. Example: In BERT, the word "bank" would have different embeddings in "river bank" and "bank account", reflecting its different meanings in these contexts.
Why Embeddings are Crucial for Large Language Models (LLMs)
Large Language Models like GPT-3, BERT, and their successors like ChatGPT, Claude, Mistral or LLaMa have revolutionized natural language processing. These models owe much of their success to the power of embeddings. Here's why embeddings are so critical for LLMs:
- Efficient Input Representation: LLMs deal with enormous amounts of text data. Embeddings provide a compact, fixed-size representation for words and sentences, regardless of their original length. This allows LLMs to process inputs efficiently. Example: Instead of dealing with variable-length sequences of characters or one-hot encoded vectors (which would be enormous for large vocabularies), LLMs can work with fixed-size embedding vectors for each token.
- Capturing Semantic Relationships: Embeddings encode semantic meanings, allowing LLMs to understand relationships between words and concepts without explicitly programming these relationships. Example: An LLM can understand that "king" is to "man" as "queen" is to "woman" simply through the mathematical relationships in their embedding vectors.
- Transfer Learning: Pre-trained embeddings allow LLMs to start with a strong understanding of language, even before task-specific training. This is a form of transfer learning that significantly improves performance and reduces training time for new tasks. Example: A model pre-trained on general text can quickly adapt to specific tasks like sentiment analysis or named entity recognition, as it already understands word meanings and relationships.
- Handling Out-of-Vocabulary Words: Advanced embedding techniques allow LLMs to generate meaningful representations even for words they haven't seen during training. Example: Subword tokenization and embedding methods like those used in BERT allow the model to handle rare words or even misspellings by breaking them into familiar subwords.
- Contextual Understanding: Modern LLMs use contextual embeddings, where the representation of a word changes based on its context. This allows for much more nuanced understanding of language. Example: In the sentences "I'm going to the bank to deposit money" and "I'm going to sit on the river bank", an LLM using contextual embeddings would represent "bank" differently, capturing its distinct meanings.
- Cross-Lingual Capabilities: Multilingual embeddings enable LLMs to perform cross-lingual tasks, understanding and generating text across multiple languages. Example: A multilingual LLM can understand that "dog" (English), "perro" (Spanish), and "chien" (French) refer to the same concept, as they would have similar embedding representations.
- Attention Mechanism Facilitation: In transformer-based LLMs, embeddings are crucial for the attention mechanism, allowing the model to focus on relevant parts of the input when generating output. Example: When translating "The man bit the dog" to French, the attention mechanism uses word embeddings to understand which words are most relevant for translating each part of the sentence correctly.
- Dimensionality Reduction: Embeddings effectively reduce the high-dimensionality of language data, making it feasible for LLMs to process and learn from vast amounts of text. Example: Instead of working with sparse vectors in a vocabulary space of hundreds of thousands of dimensions, LLMs can work with dense embedding vectors of only a few hundred dimensions.
In essence, embeddings serve as the foundation upon which LLMs build their understanding of language. They transform the complex, messy world of human language into a structured, mathematical form that machines can process effectively. This transformation is what allows LLMs to perform their seemingly magical feats of language understanding and generation.
Conclusion: The Future is Embedded
As AI continues to advance, embeddings evolve alongside it. They're the unsung heroes that allow machines to make sense of our messy, beautiful, complex world of human communication. By transforming data into a form that AIs can efficiently process, embeddings are paving the way for more intelligent, nuanced, and helpful AI systems.
The next time you're amazed by an AI's ability to understand or generate human-like text, remember the humble embedding – the secret sauce that's making it all possible.
